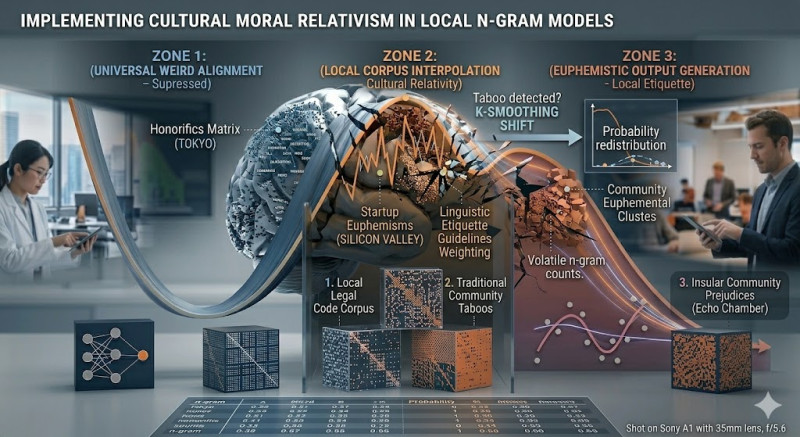
In the discourse of AI ethics, alignment is typically treated as a search for a single, universal moral framework. However, anthropologically, morality is not monolithic; it is a fluid, geographically bounded construct. While large-scale frontier transformers are engineered to reflect a homogenized, often Western-centric ethical standard (WEIRD—Western, Educated, Industrialized, Rich, Democratic), edge computing and regional applications require a different approach. For highly localized, low-resource NLP systems, implementing Cultural Moral Relativism within local n-gram models offers a lightweight, deterministic alternative to massive alignment frameworks.
The Architecture of Localized Probability
An n-gram model predicts the probability of a target word based entirely on the history of the preceding $n-1$ words. Mathematically, it calculates:
Where $C$ represents the frequency count of specific token sequences within the training corpus.
By manipulating the training corpus ($C$) at a regional level, engineers can construct a localized ethical landscape. Instead of using reinforcement learning from human feedback (RLHF) to suppress certain behaviors, the local n-gram model inherently absorbs the moral taboos, linguistic etiquette, and societal values of the specific community that generated the text.
Operationalizing Moral Relativism
Implementing cultural relativism in these models relies on two primary engineering techniques:
-
Sovereign Corpus Curation: Rather than training on global internet scrapes, the model is fed exclusively with hyper-local literature, regional legal codes, and localized community guidelines. For instance, an n-gram model deployed in a traditional corporate environment in Tokyo will calculate entirely different conditional probabilities for honorifics and workplace conflict resolution text than one deployed in a tech startup in Silicon Valley.
-
Ethical Markov K-Smoothing: Traditional smoothing techniques (like Kneser-Ney) handle zero-probability counts for unseen words. In an ethically relativized model, smoothing parameters can be artificially adjusted using "moral weight matrices." If a word sequence violates a local cultural taboo, its probability mass is dynamically redistributed to culturally preferred euphemisms, ensuring the output never breaches local ethical boundaries.
[Input Text History] ──> [Local N-Gram Matrix] ──(Taboo Detected?)──► YES ──► [K-Smoothing Shift] ──► [Euphemistic Output]
│
└──► NO ──► [Standard Statistical Output]
The Trade-Offs of Localized Alignment
The primary benefit of this approach is computational efficiency and cultural preservation. Localized n-gram models can run on low-power edge devices in isolated communities without relying on cloud-based APIs that enforce foreign ethical standards. It prevents "cultural imperialism" via AI.
However, the major risk is the echo-chamber effect. Because n-gram models lack the deep semantic understanding of transformers, a model trained on a highly conservative, insular, or radicalized local corpus will rigidly reinforce local prejudices and discriminatory linguistic patterns, mistaking historical cultural bias for absolute moral truth.
Conclusion
Implementing cultural moral relativism in local n-gram models proves that AI alignment does not always require billions of parameters or universal ethical consensus. By grounding statistical probability in the specific linguistic fabric of a local culture, we can create small, efficient language tools that respect human diversity, demonstrating that what is deemed mathematically "correct" or "good" can change entirely depending on the geography of the data.